
Los ingenieros del Instituto de Tecnología de Tokio (Tokyo Tech) han demostrado un enfoque computacional simple para mejorar la forma en que los clasificadores de inteligencia artificial (IA), como las redes neuronales, pueden entrenarse en función de cantidades limitadas de datos de sensores.

Los sensores IoT pueden estar diseñados para monitorizar diversas variables, como la cantidad de luz solar, la humedad, el movimiento, la cantidad de automóviles que cruzan una intersección o la tensión aplicada a una estructura suspendida como un puente. Estas variables evolucionan con el tiempo creando lo que se conoce como series temporales, y se espera que la información significativa esté contenida en sus cambios.
Algunos tipos de sensores miden variables que en sí mismas cambian muy lentamente con el tiempo, como la humedad. En tales casos, es posible transmitir cada lectura individual a través de una red inalámbrica a un servidor en la nube, donde se lleva a cabo el análisis de grandes cantidades de datos agregados. Sin embargo, cada vez más aplicaciones requieren medir variables que cambian bastante rápido. Dado que a menudo se requieren muchas lecturas por segundo, se vuelve poco práctico o imposible transmitir los datos sin procesar de forma inalámbrica, debido a las limitaciones de la energía disponible, los cargos por datos y, en ubicaciones remotas, el ancho de banda.
Extracción de los datos de entrenamiento
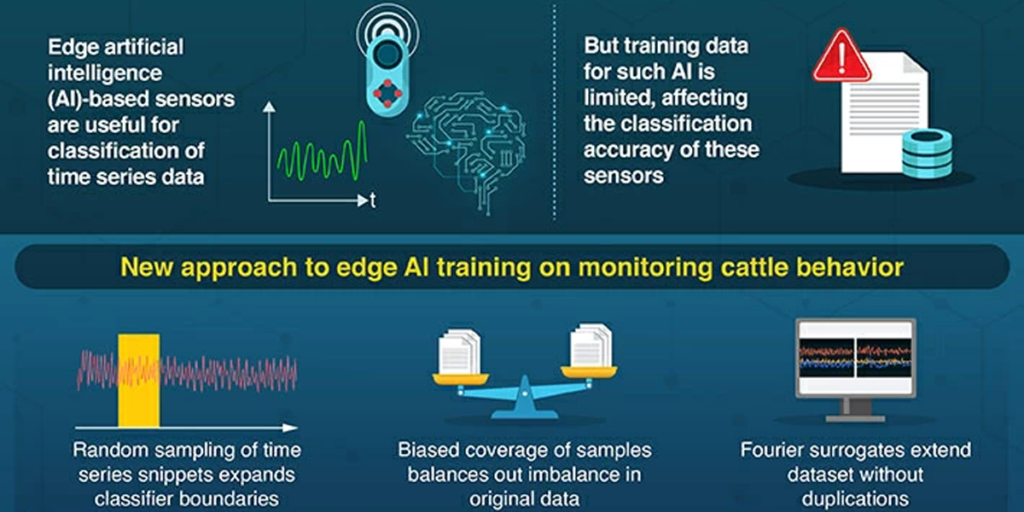
Para solucionar este problema, la investigación computacional realizada por los investigadores de Tokyo Tech ofrece una solución para disponer de datos de entrenamientos de calidad para entrenar a los dispositivos de inteligencia artificial de última generación con datos limitados. Para ello, los investigadores aplicaron dos enfoques.
El primero se conoce como muestreo, y consiste en extraer ‘fragmentos’ de series temporales correspondientes a las condiciones a clasificar siempre a partir de instantes distintos y aleatorios. La cantidad de fragmentos que se extraen se ajusta cuidadosamente, lo que garantiza que uno siempre termine con aproximadamente el mismo número de fragmentos en todos los comportamientos que se clasificarán, independientemente de cuán comunes o raros sean. Esto da como resultado un conjunto de datos más equilibrado, preferible como base para entrenar cualquier clasificador como una red neuronal.
El segundo se conoce como datos sustitutos e implica un procedimiento numérico muy robusto para generar, a partir de cualquier serie temporal existente, cualquier número de series nuevas que conserven algunas características clave, pero que no estén correlacionadas en absoluto.
Las series temporales sustitutas se generan codificando completamente las fases de una o más señales, lo que las hace totalmente irreconocibles cuando se consideran sus cambios a lo largo del tiempo. Sin embargo, la distribución de valores, la autocorrelación y la correlación cruzada, se conservan perfectamente.