
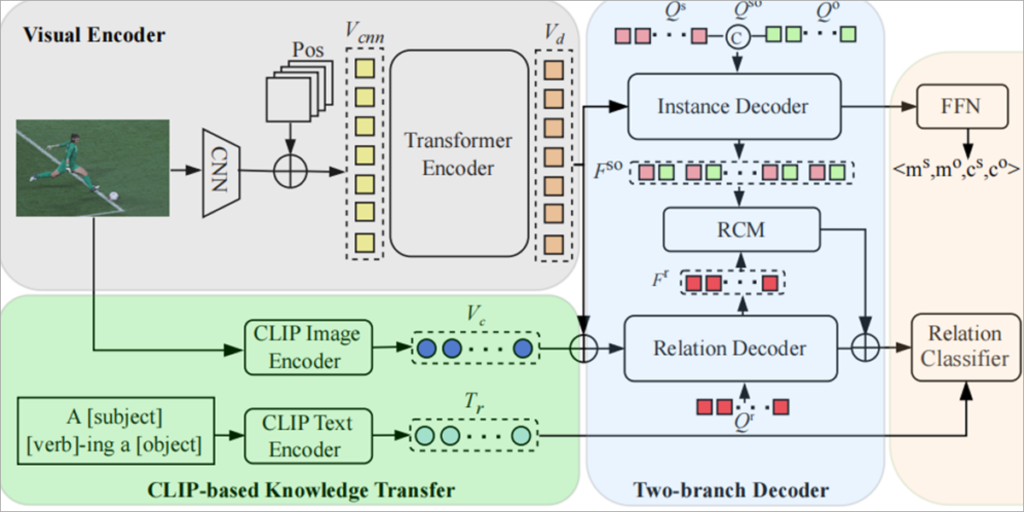
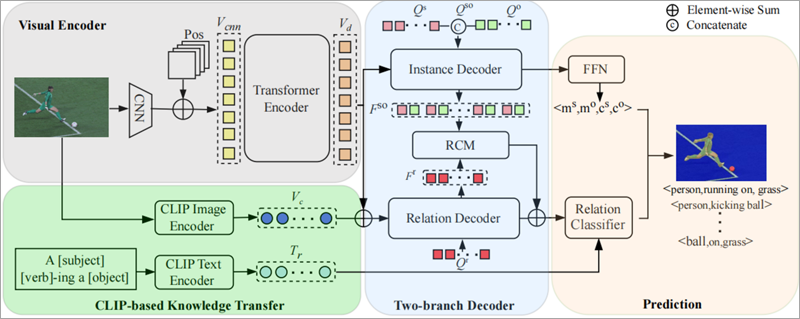
Para abordar el problema de la distribución de cola larga en la visión por computadora, los investigadores de la Academia de Ciencias de China (CAS) han propuesto un marco novedoso llamado transferencia de conocimientos basada en clips y minería de contexto relacional (CKT-RCM).

Panoptic Scene Graph (PSG) es una dirección de investigación destacada dentro de la generación de gráficos de escena, que requiere una salida completa de todas las relaciones en una imagen junto con una segmentación precisa para la localización de objetos. PSG tiene como objetivo mejorar la comprensión de escenas mediante modelos de visión por computadora y respaldar tareas posteriores como la descripción de escenas y la inferencia visual.
Análisis de la percepción humana en las relaciones con objetos
En este estudio, los investigadores exploraron cómo los humanos perciben las relaciones con los objetos, presentando dos perspectivas clave. Por un lado, la gente anticipaba las relaciones con los objetos basándose en el sentido común o el conocimiento previo. Por otro lado, también infirieron relaciones basadas en información contextual entre sujetos y objetos.
Estas perspectivas subrayan la importancia de aprovechar el conocimiento previo, llevando a cabo una corrección de sesgos de datos utilizando datos externos previamente observados por humanos, así como realizar una distribución previa de condiciones entre objetos.
Los investigadores desarrollaron este marco de red CKT-RCM basándose en el modelo clip de visión y con un lenguaje previamente entrenado. CKT-RCM facilita la inferencia de relaciones durante los procesos de Panoptic Scene Graph e integra un mecanismo de atención cruzada para extraer el contexto relacional, asegurando un equilibrio entre valor y calidad en las predicciones relacionales.
Este estudio contribuye a la comprensión y percepción de escenas por parte de robots y vehículos autónomos.