Los modelos de lenguaje grande (LLM) que se entrenan exclusivamente con texto tienen una comprensión sólida del mundo visual. Pueden escribir código de representación de imágenes para generar escenas complejas con objetos y composiciones intrigantes, e incluso cuando ese conocimiento no se utiliza correctamente, los LLM pueden refinar sus imágenes. Los investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del Instituto Tecnológico de Massachussets (MIT) observaron esto cuando solicitaron a los modelos de lenguaje que autocorrigieran su código para diferentes imágenes, donde los sistemas mejoraron sus simples dibujos de imágenes prediseñadas con cada consulta.
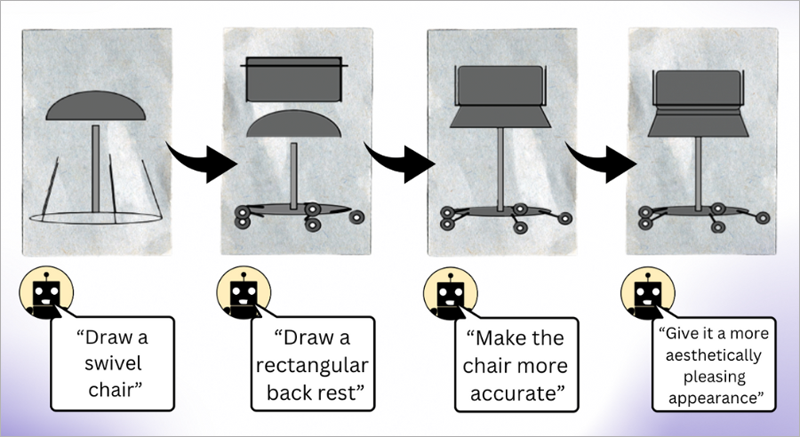
El conocimiento visual de los modelos de lenguaje se obtiene a partir de cómo se describen conceptos como formas y colores en Internet, ya sea en lenguaje o código. Cuando se les da una instrucción como ‘dibujar un loro en la jungla’, los usuarios activan el LLM para considerar lo que se leyó en las descripciones anteriores.
Para evaluar cuánto conocimiento visual tienen los LLM, el equipo de CSAIL construyó un chequeo de la visión para los LLM, utilizando su conjunto de datos de aptitud visual, que probaron las habilidades de los modelos para dibujar, reconocer y autocorregir estos conceptos. Al recopilar cada borrador final de estas ilustraciones, los investigadores entrenaron un sistema de visión por computadora que identifica el contenido de fotografías reales.
Para construir este conjunto de datos, los investigadores primero consultaron los modelos para generar código para diferentes formas, objetos y escenas. Posteriormente, compilaron ese código para representar ilustraciones digitales simples, como una fila de bicicletas, lo que demuestra que los LLM comprenden las relaciones espaciales lo suficientemente bien como para dibujar los vehículos de dos ruedas en una fila horizontal.
Recopilación de imágenes para entrenar al sistema
Los investigadores reunieron estas ilustraciones, que luego se utilizaron para entrenar un sistema de visión por computadora que puede reconocer objetos dentro de fotografías reales (a pesar de nunca haber visto uno antes). Con estos datos sintéticos generados por texto como único punto de referencia, el sistema supera a otros conjuntos de datos de imágenes generados por procedimientos que fueron entrenados con fotografías auténticas.
El equipo de CSAIL cree que combinar el conocimiento visual oculto de los LLM con las capacidades artísticas de otras herramientas de inteligencia artificial, como los modelos de difusión, también podría resultar beneficioso. Los sistemas como Midjourney a veces carecen de los conocimientos necesarios para modificar constantemente los detalles más finos de una imagen, lo que les dificulta manejar solicitudes como reducir la cantidad de automóviles que se muestran en la imagen o colocar un objeto detrás de otro. Si un LLM esbozara de antemano el cambio solicitado para el modelo de difusión, la edición resultante podría ser más satisfactoria.
El equipo de CSAIL cree que este procedimiento podría ser una base para evaluar de qué manera un modelo de IA generativa puede entrenar un sistema de visión por computadora.