
Los modelos básicos son modelos masivos de aprendizaje profundo que se han entrenado previamente con una enorme cantidad de datos de uso general sin etiquetar. Se pueden aplicar a una variedad de tareas, como generar imágenes o responder preguntas de los usuarios, pero estos modelos pueden ofrecer información incorrecta o engañosa. Para solventar este problema, los investigadores del Instituto Tecnológico de Massachusetts (MIT) y del MIT-IBM Watson AI Lab han desarrollado una técnica para estimar la confiabilidad de los modelos de inteligencia artificial (IA) base antes de implementarlos en una tarea específica.

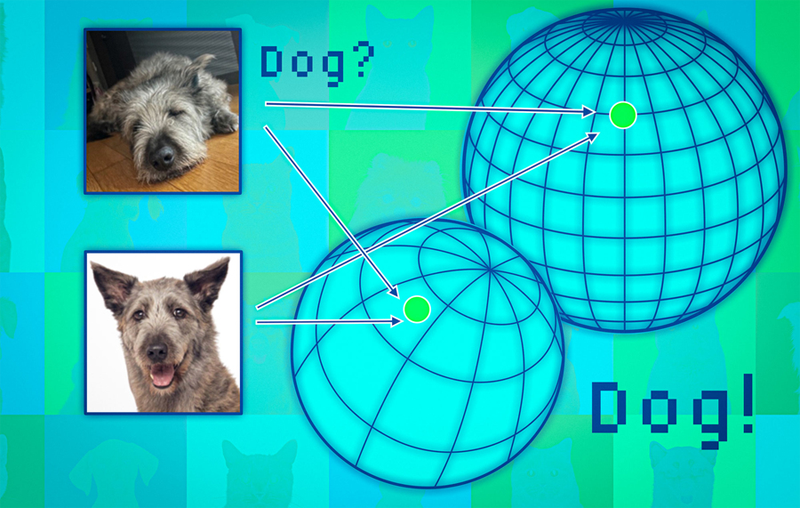
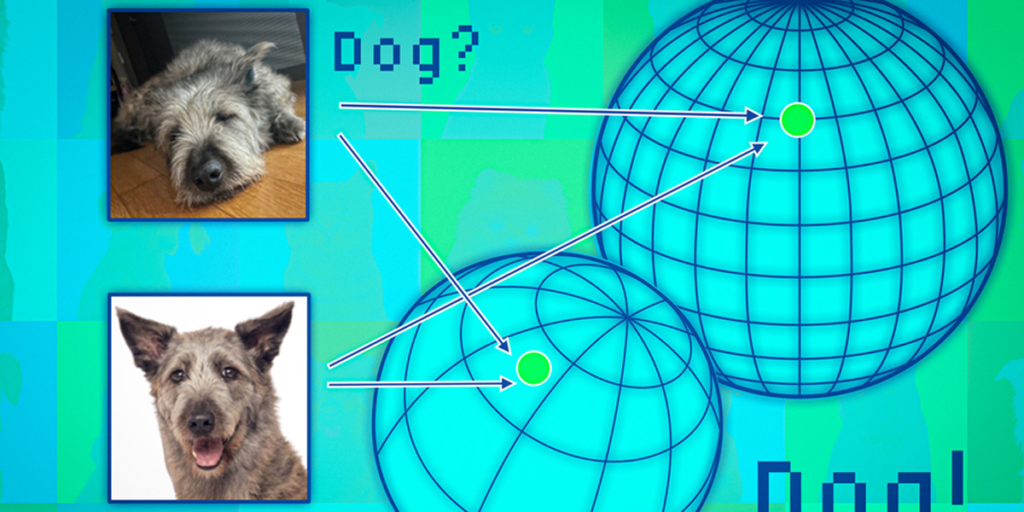
Con el objetivo de ayudar a prevenir tales errores, el MIT y del MIT-IBM Watson AI Lab han utilizado un enfoque conjunto entrenando varios modelos que comparten muchas propiedades, pero son ligeramente diferentes entre sí. Sin embargo, tuvieron el inconveniente de cómo comparar una representación abstracta. Resolvieron este problema utilizando una idea llamada consistencia de vecindad.
El método de los investigadores prepara un conjunto de puntos de referencia fiables para ponerlos a prueba en el conjunto de modelos. Posteriormente, para cada modelo, investigan los puntos de referencia ubicados cerca de la representación del punto de prueba en ese modelo. Al observar la consistencia de los puntos vecinos, pueden estimar la confiabilidad de los modelos.
Para verificar que el modelo es fiable, se aplicó un algoritmo que evalúa la coherencia de las representaciones que cada modelo aprende sobre el mismo punto de datos de prueba.
Cuando probaron este enfoque en una amplia gama de tareas de clasificación, descubrieron que era mucho más consistente que las líneas de base. Además, no se vio obstaculizado por puntos de prueba desafiantes que hacían que otros métodos fallaran.
Evaluación de la confiabilidad
Además, su enfoque se puede utilizar para evaluar la confiabilidad de cualquier dato de entrada, de modo que se podría evaluar cómo funciona en un modelo para un tipo particular de individuo, como un paciente con ciertas características.
Asimismo, se podría usar esta técnica para decidir si un modelo debería aplicarse en un contexto determinado, sin necesidad de probarlo en un conjunto de datos del mundo real. Esto podría ser especialmente útil cuando los conjuntos de datos pueden no ser accesibles debido a preocupaciones de privacidad, como en los entornos de atención médica. La técnica también podría aplicar para clasificar modelos en función de puntajes de confiabilidad, lo que permite al usuario seleccionar el mejor para su tarea.